本文转载自: wandb: 深度学习轻量级可视化工具入门教程_紫芝的博客-CSDN博客,请直接点击链接访问原文。本页仅作为本人学习笔记,不做他用。
引言
人工智能方向的项目,和数据可视化是紧密相连的。
模型训练过程中梯度下降过程是什么样的?损失函数的走向如何?训练模型的准确度怎么变化的?
清楚这些数据,对我们模型的优化至关重要。
由于人工智能项目往往伴随着巨大数据量,用肉眼去逐个数据查看、分析是不显示的。这时候就需要用到数据可视化和日志分析报告。
TensorFlow自带的Tensorboard在模型和训练过程可视化方面做得越来越好。但是,也越来越臃肿,对于初入人工智能的同学来说有一定的门槛。
人工智能方面的项目变得越来越规范化,以模型训练、数据集准备为例,目前很多大公司已经发布了各自的自动机器学习平台,让工程师把更多精力放在优化策略上,而不是在准备数据、数据可视化方面。
wandb
wandb是Weights & Biases的缩写,这款工具能够帮助跟踪你的机器学习项目。它能够自动记录模型训练过程中的超参数和输出指标,然后可视化和比较结果,并快速与同事共享结果。
通过wandb,能够给你的机器学习项目带来强大的交互式可视化调试体验,能够自动化记录Python脚本中的图标,并且实时在网页仪表盘展示它的结果,例如,损失函数、准确率、召回率,它能够让你在最短的时间内完成机器学习项目可视化图片的制作。
总结而言,wandb有4项核心功能:
- 看板:跟踪训练过程,给出可视化结果
- 报告:保存和共享训练过程中一些细节、有价值的信息
- 调优:使用超参数调优来优化你训练的模型
- 工具:数据集和模型版本化
也就是说,wandb并不单纯的是一款数据可视化工具。它具有更为强大的模型和数据版本管理。此外,还可以对你训练的模型进行调优。
wandb另外一大亮点的就是强大的兼容性,它能够和Jupyter、TensorFlow、Pytorch、Keras、Scikit、fast.ai、LightGBM、XGBoost一起结合使用。
因此,它不仅可以给你带来时间和精力上的节省,还能够给你的结果带来质的改变。
验证数据可视化
wandb会自动选取一部分验证数据,然后把它展示到面板上。例如,手写体预测的结果、目标识别的包围盒。
自然语言处理
使用自定义图表可视化基于NLP注意力的模型
这里只给出2个示例,除了这些,它目前还有更多实用有价值的功能。而且,它还不断在增加新功能。
重要工具
wandb(Weights & Biases)是一个类似于tensorboard的极度丝滑的在线模型训练可视化工具。  wandb这个库可以帮助我们跟踪实验,记录运行中的超参数和输出指标,可视化结果并共享结果。
wandb这个库可以帮助我们跟踪实验,记录运行中的超参数和输出指标,可视化结果并共享结果。
下图展示了wandb这个库的功能,Framework Agnostic的意思是无所谓你用什么框架,均可使用wandb。wandb可与用户的机器学习基础架构配合使用:AWS,GCP,Kubernetes,Azure和本地机器。 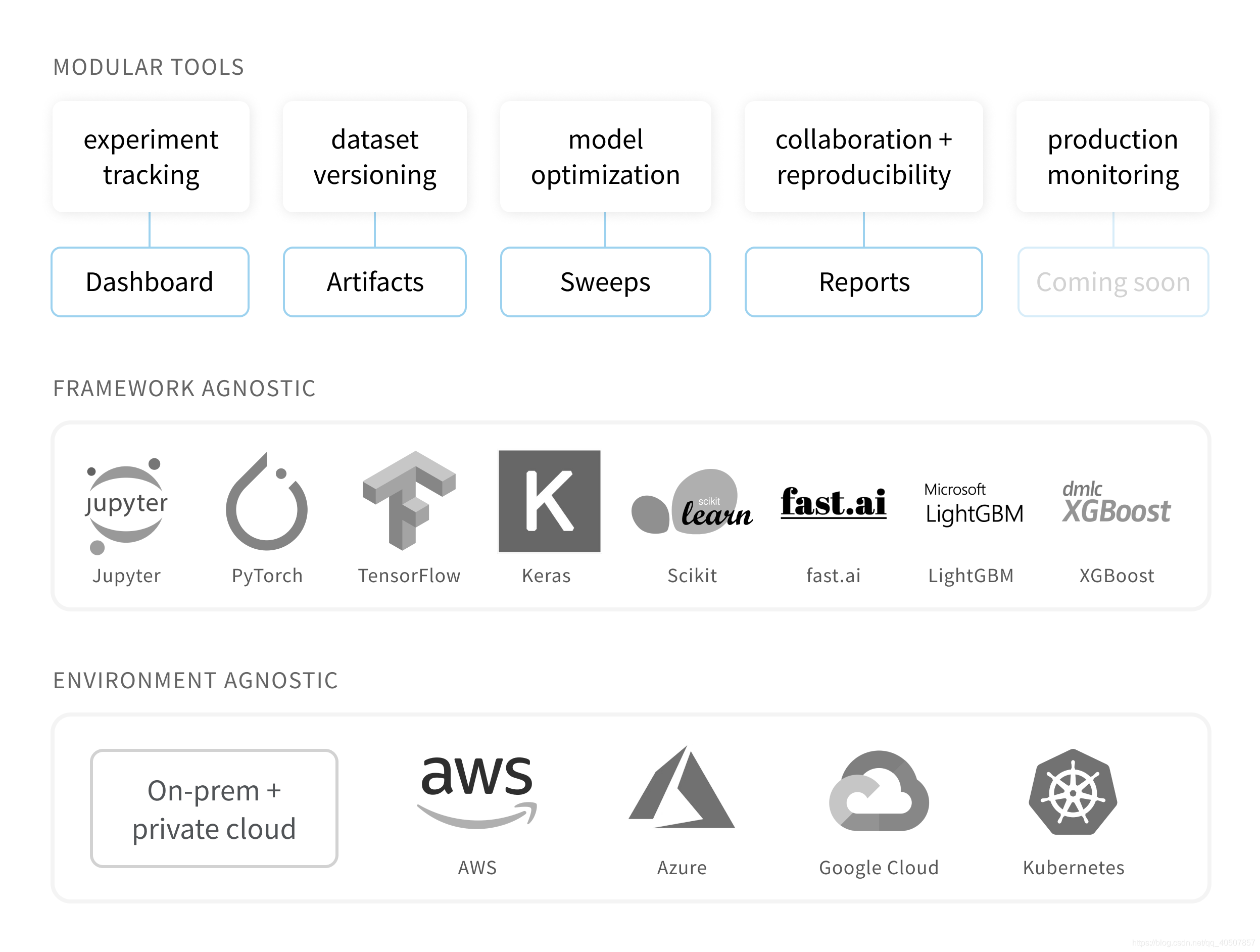
下面是wandb的重要的工具
- Dashboard: Track experiments(跟踪实验), visualize results(可视化结果);
- Reports:Save and share reproducible findings(分享和保存结果);
- Sweeps:Optimize models with hyperparameter tuning(超参调优);
- Artifacts:Dataset and model versioning, pipeline tracking(数据集和模型的版本控制);
极简教程
1 安装库
1 | pip install wandb |
2 创建账户
1 | wandb login |
3 初始化
1 | # Inside my model training code |
4 声明超参数
1 | wandb.config.dropout = 0.2 |
5 记录日志
1 | def my_train_loop(): |
6 保存文件
1 | # by default, this will save to a new subfolder for files associated |
使用wandb以后,模型输出,log和要保存的文件将会同步到cloud。
PyTorch应用wandb
我们以一个最简单的神经网络为例展示wandb的用法:
首先导入必要的库:
1 | from __future__ import print_function |
登陆你的wandb账户:
1 | # 定义Convolutional Neural Network: |
定义训练函数
1 | def train(config, model, device, train_loader, optimizer, epoch): |
定义测试函数
1 | # wandb.log用来记录一些日志(accuracy,loss and epoch), 便于随时查看网路的性能 |
初始化一个wandb run,并设置超参数:
1 | # 初始化一个wandb run, 并设置超参数 |
主函数
1 | def main(): |
