以bert-base-chinese为例,首先到hugging face的model页,搜索需要的模型,进到该模型界面。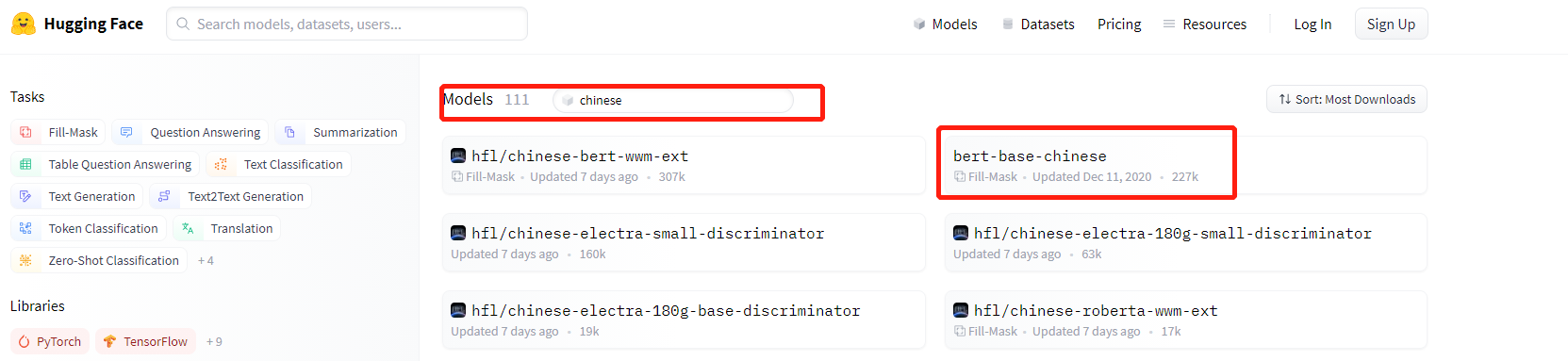
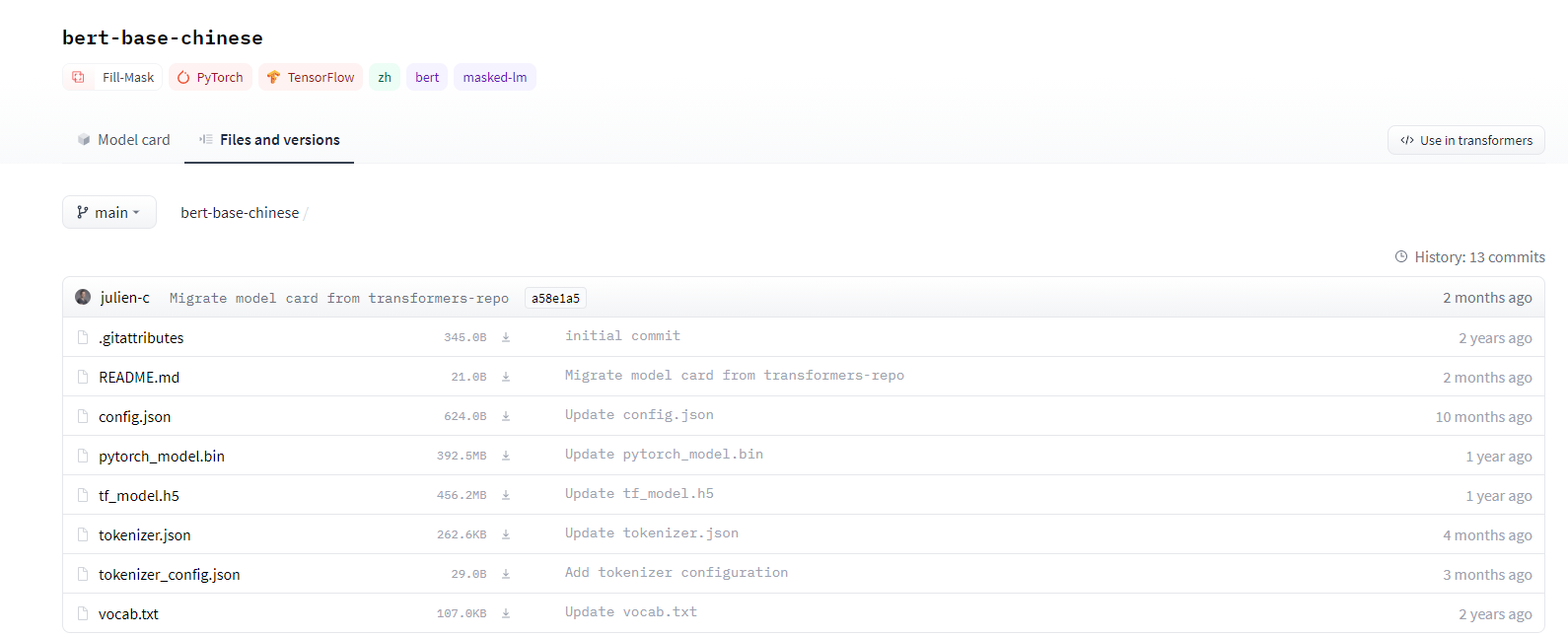
在本地建个文件夹:
mkdir -f model/bert/bert-base-chinese
将config.json、pytorch_model.bin(与tf_model.h5二选一,用什么框架选什么)、tokenizer.json、vocab.txt下载到刚才新建的文件夹中。(对于一般的模型config.json、tokenizer.json、pytorch_model.bin/tf_model.h5是必须下的,其他看情况而定,为了方便也可以把该界面的文件全部下载下来。)
怎么用下载下来的模型呢?
1
2
3
4
5
6
7
8
9
10
11
| import torch
from transformers import BertModel, BertTokenizer
tokenizer = BertTokenizer.from_pretrained("model/bert/bert-base-chinese/")
model = BertModel.from_pretrained("model/bert/bert-base-chinese/")
sentence = "今天天气怎么样?"
# add_special_tokens=True 则前后会分别加上<SOS> <EOS>的embedding
input_ids = tokenizer.encode(sentence, add_special_tokens=True)
input_ids = torch.tensor([input_ids])
with torch.no_grad():
last_hidden_states = model(input_ids)[0] # Models outputs are now tuples
# last_hidden_states.shape is (1, 8, 768)
|

