1 Series简介
Pandas 是python的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。
pandas的两大主要数据结构 Series和DateFrame,其中Series 是带标签的一维数组,可存储整数、浮点数、字符串、Python 对象等类型的数据。轴标签统称为索引,它由两部分组成。
values:一组数据(ndarray类型)
index:相关的数据索引标签
形式如下:

特点:数据对齐事内在的,标签与数据默认对齐,除非特殊情况,一般不会断开连接,因此通过索引取值非常方便,不需要循环,可以直接通过字典方式,key 获取value
2 Series 创建的几种方式
2.1 列表创建
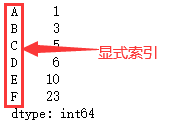
import pandas as np import pandas as pd # Series组成部分:pd.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False) lst = [1,3,5,6,10,23] s = pd.Series(lst) # 可以通过index指定索引,如果不指定索引,则会自动从0开始生成索引,我们叫做隐式索引 s

lst = [1,3,5,6,10,23] s = pd.Series(lst,index=["A","B","C","D","E","F"]) # 通过index设置显式索引 s
2.2 numpy创建
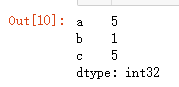
s = pd.Series(np.random.randint(1,10,size=(3,)),index=['a','b','c']) s
2.3 字典创建
dic = {"A":1,"B":2,"C":3,"D":2}
s2 = pd.Series(dic)
s2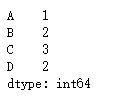
3 Series的索引和切片
因为Series只有一列,因此一般只对行进行操作,索引分为隐式索引和显示索引,因此不同的方式操作起来也不一样。
3.1 Series隐式索引的操作
lst = [1,3,5,6,10,23] s = pd.Series(lst)

s[0] 取某一行,也可以说取某个元素
s[[0,1]] 取多行时,里面则是列表,可存储多个
s[0:2] 切片操作,取0-2行,但是只能取到0和1行,顾头不顾尾
s.iloc[0:2] 使用iloc来专门对隐式索引进行相关操作,也是只能取到0和1行,顾头不顾尾
s.iloc[[0,1]] 使用iloc来专门对隐式索引进行相关操作,跟s[[0,1]]一样
这里就不一一举例了,我可是一个一个都试过的。
3.2 Series显式索引的操作
lst = [1,3,5,6,10,23] s1 = pd.Series(lst,index=["A","B","C","D","E","F"])

s1["A"] 取某行或单个元素
s1[["A","B"]] 取多行,可以是连续的,也可以是不连续的
s1["A":"B"] 切片,取A行和B行,这里的B行是可以取到的,头和尾都可以取到
s1.loc["A":"B"] 使用loc来专门对显式索引进行相关操作,这里的B行也可以取到
s1.loc[["A","B"]] 使用loc来专门对显式索引进行相关操作
总结
Series的索引和切片只针对行而言,因为它只有一列
loc是对于显式索引的相关操作(对于标签的处理),iloc是针对隐式索引的相关操作(对于整数的处理)。
我们发现其实s[0:2] 与 s.iloc[0:2]没有太大差别(显式索引也是一样),这并不说明iloc就没有用,个人觉得它更有意义的是在DataFrame当中使用,后面会讲到。
4 Series的基本操作
4.1 显示Series部分数据内容
s.head(n) 该函数代表的意思是显示前多少行,可以指定显示的行数,不写n默认是前5行
s.tail(n) 该函数代表的意思是显示后多少行,可以指定显示的行数,不写n默认是前5行
lst = [1,3,5,6,10,23] s1 = pd.Series(lst,index=["A","B","C","D","E","F"])

s1.head() # 显示前5行

s1.tail() # 显示后5行

4.2 Series去重操作
s.unique() 结果为一维数组
dic = {"A":1,"B":2,"C":3,"D":2}
s2 = pd.Series(dic)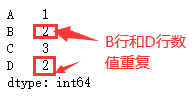
s2.unique() # 原s2并未修改,该结果返回的是一维数组

4.3 Series的相加运算
Series相加,会根据索引进行操作,索引相同则数值相加,索引不同则返回NaN
NaN在pandas解释中为 not a number ,它是float类型,表示缺失数据,可以参与运算。
# s1
lst = [1,3,5,6,10,23]
s1 = pd.Series(lst,index=["A","B","C","D","E","F"])
# s2
dic = {"A":1,"B":2,"C":3,"D":2}
s2 = pd.Series(dic)
s3 = s2+s1

4.4 Series缺失值操作
查看Series中哪些是NaN
二者都是判断是否为空,返回的结果为True或False
s.notnull() 不为空返回True,为空返回False
s.isnull() 不为空返回False,为空返回True
s3.isnull()

s3.notnull()

需求1:只显示不为空的行
s3[s3.notnull()]
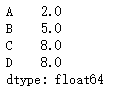
需求2:只显示为空的行
s3[s3.isnull()]
