OpenQA论文阅读(十一) Learning to Retrieve Reasoning Paths over Wikipedia Graph for Question Answering

论文标题:LEARNING TO RETRIEVE REASONING PATHS OVER WIKIPEDIA GRAPH FOR QUESTION ANSWERING
论文出处:ICLR2020
原文链接:Learning to Retrieve Reasoning Paths over Wikipedia Graph for Question Answering
开放领域多轮问答:Open Domain Multi-hop QA
开放领域的问答指的是从一个超大(但不是无限)的数据库中找到问题的答案。过去的方法大都是先从这海量的数据中抽取出相关的少量文档,然后把当做一个基于给定文本的问答问题处理。尽管这种方法对单轮问答(sigle-hop QA)很好使,但是在多轮问答(multi-hop QA)中却往往不那么奏效。所谓单轮问答,就是问题的答案就在单个文档中,而多轮问答需要结合很多篇文档的“知识推理”才能得到最终的答案。比如下图所示:
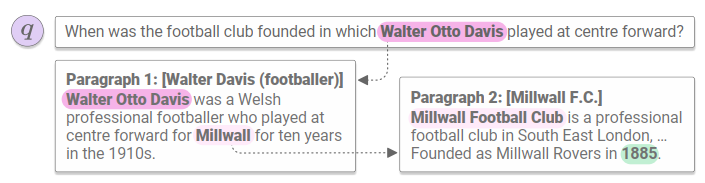
开放领域的多轮问答是一个非常大的挑战,它不但要求我们能准确提取“所有”的相关文档,还要求能基于这些文档做知识推理,不可谓不困难。本文的方法大致可以分为两步,一是通过维基百科的超链接构建一个维基百科图网络,在不同的文档之间建模;二是使用一个RNN给推理路径建模,从而找到最佳推理路径。
方法
本文提出的模型结构如下所示:
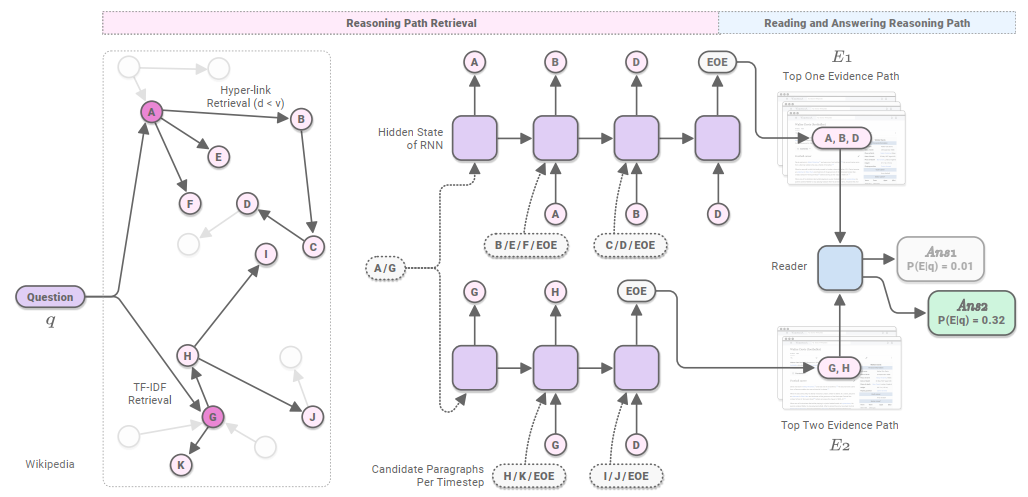
首先,一个推理路径提取器根据维基百科之间的超链接关系得到若干推理路径,然后一个阅读理解模型基于这些路径找到最可能的一条路径作为最终的答案。本文用维基百科文章里的每个段落p 作为基本单元。给定问题q模型首先找到一条推理路径E=[p1,⋯,pk],用Sretr(q,E)表示;然后在E中找到答案a用Sread(q,E,a)表示。所以,其得分可以为:argmaxE,aS(q,E,a)s.t.S(q,E,a)=Sretr(q,E)+Sread(q,E,a)
推理路径提取
路径提取器根据维基百科之间的关系构建一个图网络G
构建图网络:我们直接用维基百科里的超链接构建有向图G,注意到图的每个结点代表一个段落而不是一篇文章。这个图离线构建即可。
循环路径提取:在构建好图G之后,我们就要去提取路径了。我们使用RNN作为基干模型。在第t步,模型从候选段落集Ct中选择一个段落pi,然后再把pi联系的段落作为下一步的候选集Ct+1,继续这个过程,直到生成特殊符号[EOE]。具体来说:
wi=BERT[CLS](q,pi)∈RdP(pi∣ht)=σ(wi⋅ht+b);ht+1=RNN(ht,wi)∈Rd
这么做的好处是,可以基于先前选取的段落捕捉推理路径上段落之间的关系,并且由于RNN的可变长性,可以得到很长的推理路径。
候选段落的BeamSearch:如果候选集很大,那么计算上式的开销就很大,为此,需要从中选取一部分。具体来说,第一个候选段落集C1被初始化为使用TF-IDF和问题q最相近的F个段落的集合。而其他的候选集合不变。除此之外,我们还对推理路径使用Beam Search。对于推理路径,它的得分可以定义为p(pi∣h1),⋯,p(pk∣h∣E∣)的乘积。 这样一来,就可以得到B个得分最高的路径集合E={E1,⋯,EB}
数据增强:为了训练多轮QA,我们首先得到一个真值推理路径g=[p1,⋯,p∣g∣],然后增加一条新的推理路径gτ=[pτ,p1,⋯,p∣g∣],这里pτ∈C1是TF-IDF分最高的一个段落,并且和p1相联系。
负采样:我们使用两种负采样策略:(1)基于TF-IDF的,(2)基于超链接的。单轮QA只用(1),多轮QA两者都用,负采样数为50。
损失函数:损失函数可以定义为:
Lretr(pt,ht)=−logP(pt∣ht)−∑p~∈C~tlog(1−P(p~∣ht))
其中p~∈C~t是负样本集合。
阅读理解回答
阅读理解器首先对所有路径re-rank,然后从最有可能的路径中抽取答案。具体来说,对每条路径,先用BERT得到特征表示,再用sigmoid得到该路径的概率,我们只需要取概率最高的路径Ebest即可。然后再找最大的问答文段起始位置概率和结束位置概率乘积。
除了使用真值作为训练目标外,还可以使用distantly supervised样本。最后,把包含答案的一个段落替换为TF-IDF最高得分的一个段落,记为E~,然后去最小化P(E~∣q)。从而,损失函数为:Lread=Lspan+Lno-answer=(−logPystartstart−logPyendend)−logPτ这里,Lno-answer是re-rank模型的损失,也就是最小化P(E~∣q)的损失。
实验
我们在HotpotQA, SQuAD Open和Natural Question Open上实验,其他设置详见原文。
下表是在HotpotQA验证集上的结果。显然,本文的方法几乎全方位吊打其他模型。