论文R3: Reinforced Reader-Ranker for Open-Domain Question Answering
论文地址:https://arxiv.org/pdf/1709.00023.pdf
代码地址:https://github.com/shuohangwang/mprc [尚未阅读/复现]
备注:暂时忽略强化学习部分
本文是一篇2017年AAAI会议的问答系统,其认为当前大多数的问答都是基于事先提取好的候选文本作为抽取答案的passage,而并不符合实际应用;在实际中,需要结合信息检索方法来自主地搜索与问题相关的passage并进行答案的抽取,这一过程非常繁琐,且依赖于检索的候选passage的质量。本文则提出Searcing-Reading QA(SR-QA)方 法,并使用深度强化学习进行训练。
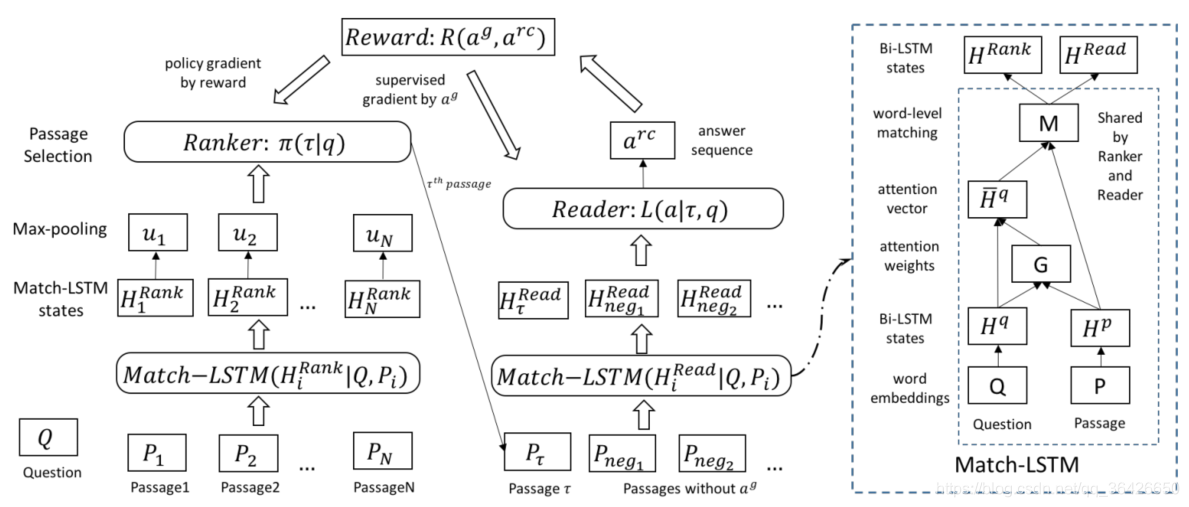 图一 网络结构
图一 网络结构 问题提出
当询问“What is the largest island in the Philippines?”,需要使用信息检索工具来获取可能与之相关的文本,如图所示:

可发现,信息检索工具提供了3个文本材料,并按得分降序排列。作者使用BM25算法完成检索可知P1虽然与问题很相关,可是并没有所需要的答案;P3虽然包含于答案有关的关键词,但其并没有回答与问题相关的内容,而只有P2才包含答案内容。因此可知信息检索工具的检索并不能确保答案存在,引入不包含答案的文本作为噪声会对模型产生影响。
BM25算法
BM25算法是一种为检索工具进行打分的算法。简单的来说,给定一个检索语句,首先使用分词工具将该语句切分若干个语素(也可理解为实体词),每个语素可根据IDF计算其相对权重,其次每个语素也可以根据设计的得分函数计算其与每篇文档的相关性,最后对每个语素加权求和后即可得到得分。

参考资料:BM25算法, Best Matching - 知乎 (zhihu.com);BM25 调参调研 - 疯狂的拖鞋 - 博客园 (cnblogs.com)
因此,本文提出一种 Reinforced Ranker-Reader 问答模型,其包含三个主要模块:
IR检索层:如BM25算法、TFIDF算法等等,本文未介绍。
Ranker排序层:目标是根据检索工具获取的候选passage,分别计算其可能存在答案的概率,并形成概率分布,基于该概率分布挑选最有可能包含答案的passage;
Reader阅读层:在训练阶段,如果挑选的passage包含答案,则进行反向梯度传播来更新参数。
模型
Match-LSTM:
使用Match-LSTM作为编码层。该模型主要目的是实现“带着问题读文章”的过程。即在对passage进行编码时,每读取一个token时,都判断其与question的所有token的相关性,因此passage的每个token都会得到其对question的注意力权重分布并对question加权求和。
给定一个问句Q和文章P,其最大长度分别为P,Q,使用参数共享的双向LSTM进行编码:
Hp=BiLSTM(P)
Hq=BiLSTM(Q)
其中Hp∈Rl×P 表示passage的编码,Hq∈Rl×Q表示question的编码。对于P 的每个token,其与Q进行权重计算,所有P的token都进行计算后即可得到:
G=SoftMax((WgHq+bg⊗eQ)THp)
其中Wg∈Rl×l,bg∈Rl,表示可训练的参数,而G∈RQ×P则表示权重矩阵,其某一列则表示某个passage的token对应的question各个token注意力的权重。因此有 Hq=HqG。最终可以得到passage融合question的编码信息:
M=ReLU⎝⎜⎜⎜⎛Wm⎣⎢⎢⎢⎡HpHqHp⊙HqHp−Hq⎦⎥⎥⎥⎤⎠⎟⎟⎟⎞
其中⊙表示元素对应积。矩阵 M 则可以表示“带着问题读文章”后每个token的信息。当然事实上我们在读完文章后会回头去总结,这一过程则可以再次使用一次LSTM来完成,即:Hm=BiLSTM(M).
在Ranker部分,需要根据每个问题分别去与各个passage进行计算,因此这一过程可以使用Match-LSTM,最终得到每个passage融合问题的表征向量,记做 HRank ;同理在Reader部分是给定问句和挑选的某个passage,依然可以再次得到一个passage的表征向量,记做 HRead 。在具体实验中,Ranker使用1层LSTM,Reader使用3层LSTM。
Ranker:
Ranker部分目标是计算每个候选passage可能存在答案的概率分布,公式如下:
uiCγ=MaxPooling(HiRank)=tanh(Wc[u1;u2;…;uN]+bc⊗eN)=Softmax(wcC)
Reader:
本文将Reader的目标设计为预测passage中的start和end两个位置,即start和end及其之间的作为抽取的答案。因此需要进行两步,每一步都来预测passage的各个token可能作为start或end的概率分布,即:
Fs=tanh(Ws[HτRead;Hneg1Read;…;HnegnRead]+bs⊗eV)
βs=Softmax(wsFs)
第一行表示将抽取的passage和其他未抽取的passage(当做负样本)一同喂入线性层和softmax层后得到概率分布,得到start的预测概率,同理可以得到end的预测概率。需要注意的是,两步预测使用的参数不共享。
损失函数定义为:
L(ag∣τ,q)=−log(βaτss)−log(βaτee)
强化学习部分
略
实验
实验选择5个数据集,分别为:
- Quasar-T:专门为SR-QA设计的,每个问句都对应检索工具挑选的100个passage;
- SQuAD:是由斯坦福NLP设计的问答,其包含Q、A以及人工选择的passage;本文只使用Q和A,不使用提供的passage,组成的数据集叫做 SQuAD(open);
- WikiMovies:与电影有关的问题答案配对,可直接从维基百科上搜索passage;
- CuratedTREC:是基于TREC的开放领域问答;
- WebQuestion:专门为知识图谱问答(KBQA)设计的问答系统,本文也只是用QA对,不使用知识库;

总结
本文章首次将强化学习应用在开放领域问答(SR-QA)中,因为在判断哪个passage存在答案时,由于passage并没有标注这个标签,所以我们可以使用强化学习去自己学习,这很好的避免一些其他SR-QA工作中需要启发式的远程监督标注策略(例如当句子包含答案就认为这个passage是相关的。
本文也有一些缺点,例如该工作依然是抽取式找答案的过程,而如果检索到的所有的passage中都不存在答案的区间,那这个训练过程就是无意义的,且这些passage都将是噪声。另外,作者是基于句子进行抽取的,而有些答案可能存在跨句子的情况,或者答案存在多个句子里,因此在Ranker采样时不能只采一个passage,而应该设定一个阈值来采样多个。
参考资料
- 论文解读: R3:Reinforced Ranker-Reader for Open-Domain Question Answering_夏栀的博客-CSDN博客